My Research Workflow
November 3rd, 2023 | Published in Personal
Here is a section of a little piece I wrote for fellow PhD candidates at my university, outlining my research process.
Bibliography Creation
One of the first steps is to find documents to start your research. Historically, it would have been index cards and, more recently, search engines. You will inevitably have to look up the sources and download or retrieve them to find more papers.
One tool that I enjoy is Litmaps. You still do the initial search, but with ten items or fewer, you can upload your bibliography to the site. It automatically collects references for your items, finds intersections, and suggests additional resources.
So, in a nutshell, what it does is look at the references in your papers, sees which references your papers seem to have in common that are not part of your current bibliography and suggests them. In essence, it will help fill the gaps that may be in your current bibliography.
Cost: Free (limited)
Price: $12.50 / month
Document & Reference Management
Keeping track of our bibliographies is always an essential process for doing research. I used a couple of items over the last two or three years, but the one I have enjoyed the most is ReadCube. Here are a couple of features that I enjoy:
- You can upload your bib file from LitMaps, highlight the items you want to find, right click, and ‘Locate PDF.’ It will then automatically go out and find all the PDFs it can.
- It acts as an online storage for all your PDFs.
- You can open the PDFs online, take notes, highlight sections, etc., and it will save your notes for you online. You can also export the PDF with your notes on the document.
- Grouping of documents into categories.
- Export your references into bib files or other formats.
- Browser plugin.
Price: $60/year for an academic account
https://www.zotero.org/ or https://www.mendeley.com/ is a great runner-up.
ChatGPT with your documents
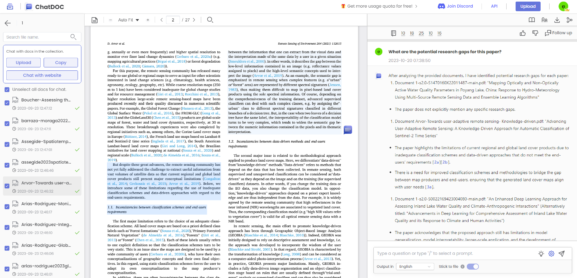
Now that we have our documents and references, it is time to research. With the recent advent of ChatGPT, it is now easier than ever to ask GPT questions about the documents you have collected. For instance, some of these questions are now called prompts, and a specific prompt can yield exciting results, making you a better researcher. For example:
- Please summarize the following document and highlight some of the key findings.
- Are there any potential research gaps in this paper?
Now, several open-source and paid projects allow you to have ChatGPT view your whole collection of documents as their source of information. This repository will enable you to get custom results/data from all the papers you are looking at.
Open-Source:
https://github.com/mayooear/gpt4-pdf-chatbot-langchain
Price: $5.99 / month
Overleaf Tips and Tricks
I am working on a survey paper that will become a section or two of my dissertation. As part of this work, I am collecting data as I write this. This process makes writing specifics difficult, as I am dealing with a moving train. Or, to put it another way, any text, chart, or table that I write that mentions some statistics could be outdated as I collect more data.
To get around this, I store everything in a database to the extent that I can. Then, I written scripts to create my charts and tables. Then, I refer to the location of the table text and not a static file, which is included in my paper. I have even made a text file containing information about my research that updates automatically. As an example, take the following sentence:
"In this survey article, the authors reviewed \readdatfile{TotalPapersAnalyized}
articles that analyzed a total of \readdatfile{TotalNumberOfSamplesAnalyized}
water samples."
The text file would just be a series of items like this:
TotalPapersAnalyized = 38 TotalNumberOfSamplesAnalyized= 425,541
Add this bit of code in your main.tex file:
\usepackage{datatool}
\DTLsetseparator{ = }% Set the separator between the columns. It could be
\DTLloaddb[noheader, keys={thekey,thevalue}]{mydata}{data/data.txt}
\newcommand{\readdatfile}[1]{\DTLfetch{mydata}{thekey}{#1}{thevalue}}
You can follow this Word document tutorial to replicate the process. https://www.lifewire.com/insert-a-document-into-another-word-3540125
Online Resources
Finally, I would like to recommend Dr. Andrew Stapleton’s YouTube channel. It covers all kinds of new tools that are great for academia and opining on the joys and stresses of being a Ph.D. student. https://www.youtube.com/@DrAndyStapleton
Hope you have enjoyed this brief note, and if you have any questions or tools you like, please let me know!